Advanced Systems
In the previous examples we've seen how to create entities with their components and then systems that based on those components execute specific actions. In this chapter we'll review more advanced uses of systems, each possible system type and what's their most common use.
System dependencies
Let's continue where we left the immediate renderer example. In this example we had several components that define circles in the screen a system that updates the position of every circle, and a render system that draws all the circles. Let's modify it so the circles not only move around but also change in size. For that let's first add new Phase and BaseSize components that will allow us to have different sizes for every circle while they change:
#[derive(Clone, Copy, Debug, Serialize, Deserialize, Component)]
struct Phase(f32);
#[derive(Clone, Copy, Debug, Serialize, Deserialize, Component)]
struct BaseSize(f32);
Let's add them to every entity:
for i in 0..100 {
scene.new_entity()
.add(Name(format!("Circle {}", i)))
.add(Position(pnt2(rand::random::<f32>() * w, rand::random::<f32>() * h)))
.add(Size(rand::random::<f32>() * 90. + 10.))
.add(BaseSize(rand::random::<f32>() * 90. + 10.))
.add(Phase(rand::random::<f32>() * 2. - 1.))
.add(Velocity(vec2(rand::random::<f32>() * 20. - 10., rand::random::<f32>() * 20. - 10.)))
.add(Color(rgba!(rand::random(), rand::random(), rand::random(), 0.1)))
.build();
}
And now let's add a new system that changes the size of each circle:
#[update_system(name = "update size")]
fn update_size(clock: &Clock, entities: Entities, resources: Resources) {
let delta = clock.game_time_delta().as_seconds() as f32;
for (size, phase, base) in entities.iter_for::<(Write<Size>, Write<Phase>, Read<BaseSize>)>() {
phase.0 += delta;
size.0 = (phase.sin() * 0.5 + 0.5) * base.0;
}
}
The system goes through every entity with size, phase and base size and updates the phase adding the delta to it then uses the phase to calculate the new size of the circle.
Finally in order for this system to run we need to add it to the scene:
scene_builder.add_update_system(update_size);
Now if we run the application the circles not only move but also change in size. If we run it using the stats and gui features with:
cargo run --features=gui,stats
In the cpu stats tab in the gui we can now see both update systems and can even stop one or the other which is sometimes useful for debugging.

Another advantage of dividing the functionality in simple systems is that systems run in parallel. The two update systems will now run at the same time and although in this case it's surely not a huge advantage given how little time they take to calculate, in larger applications it can make a big difference.
But how does rin know which systems can run in parallel, simultaneously? In the default mode in principle any system we create will be run in parallel. The main problem we encounter when running code in parallel is accessing the same data for writing. If two different systems would access the same component and write to it at the same time the data would end up in a state that is not correct.
Another problem that arises with dividing the application functionality in systems is deciding which systems run first, the order of execution. In the previous example the two update systems are completely independent and so they can run simultaneously or one after the other no matter the order. We can update the position and then the size or the size and then the position but we want the render system to run after updating the data, after both update systems have run.
The main tool to avoid this problems in rin are system dependencies. System dependencies allow us to express which systems depend on which so they run in the correct order and which systems read and write to which data to avoid two systems that write to the same data from ever running simultaneously.
The type of system dependencies available in rin right now are the following:
Needs / Updates
In order to add system dependencies we use annotations, as we've already used in the adding movement chapter. Let's add them to our systems in the immediate render with size example:
#[update_system(name = "update position")]
#[updates("Position", "Velocity")]
#[needs("Velocity")]
fn update_position(clock: &Clock, entities: Entities, resources: Resources) {
// ...
#[update_system(name = "update size")]
#[updates("Size", "Phase")]
#[needs("BaseSize")]
fn update_size(clock: &Clock, entities: Entities, resources: Resources) {
// ...
#[render_system(name = "render system")]
#[needs("Position", "Size", "Color")]
fn render_system(
gl: &gl::Renderer,
viewport: Rect<i32>,
entities: EntitiesThreadLocal,
resources: ResourcesThreadLocal
){
// ...
The idea behind the system of dependencies is expressing which components or resources each system needs or updates. That way if two systems for example update the component Position rin won't run them at the same time. This also solves the problem of the order of execution. Since the system update_position updates Position and the render_system needs Position, update_position will always run before render_system. This is a really easy way to express order of execution without really knowing how every system in the application depend on each other, only through dependencies on data, not directly on other systems.
When a rin application runs for the first time after setting up the scene, it internally creates a dependencies graph using the dependencies information and from there on it'll use that dependency graph to run the systems in the correct order and avoid two systems that write to the same data from running simultaneously.
Sometimes we might have expressed a circular dependency in which case rin will panic with a message explaining the problem so we can take the right measures to solve it.
Reads / Writes
As we've seen when we've first run the application, dependencies are not really needed and their only function is to express how systems depend on each other to determine and order of execution and avoid systems from concurrently trying to write to the same data.
Sometimes, for example when a circular dependency happens we need to decide if the dependency for a certain system is really a need or update or we just need to protect against simultaneous access. Some systems might update a certain component but not need the latest version of it, in such cases there's no need to express such dependency which helps solving circular dependencies. Then we can always use:
#[writes("Position")]
#[reads("Velocity")]
To express that a system writes or reads from those components but doesn't necessarily need to run before or after other systems that might update or need them. That allows systems that write to the same component or resource to not run simultaneously without specify an specific order.
Artificial dependencies
Dependencies on data can even be artificial, on types that are not really used but allow to specify relations of dependencies. For example, the rin system that updates all the Nodes to calculate their global position, rotation and scale and it's transformation matrices, depends as a needs on rin::graphics::NodeParts which is an empty type that is only used as a dependency and is never really added to the scene.
This type can be used by systems in applications to express that they are updating or need only the local parts of the Node, while depending on the Node itself expresses that we need also the global parts of it.
For example:
#[system(name = "update position")]
#[updates("NodeParts")]
fn update_position(entities: Entities, resources: Resources) {
// ...
#[system(name = "render")]
#[needs("Node")]
fn render(entities: Entities, resources: Resources) {
// ...
And where update_nodes is the system that hierarchically updates the global components and transformation matrices of every node in the scene.
We would end up with a dependency graph like:
update_position -> update_nodes -> render
Since update position updates NodeParts, update_nodes needs NodeParts and updates Node and render needs Node.
After / Before
Until now, all the dependency types depended on data, on types that our systems use or even on artificial dependencies, types that we don't really use but help express partial dependencies or similar. In the case of after / before dependencies, we don't depend on data but directly from system to system.
This are usually the least used since our systems are running in parallel with systems from rin itself and also from external bundles for which we usually don't know the systems names so expressing dependencies in terms of data makes things easier since we only need to know which data we are using instead of what other systems there are in the application.
Even with that in some cases, mostly for systems that are related and usually in the same module or crate we can use after / before:
#[system(name="system A")]
fn system_a(entities: Entities, resources: Resources) {
// ...
}
#[system(name="system B")]
#[after("system_a")]
fn system_b(entities: Entities, resources: Resources) {
// ...
}
or:
#[system(name="system A")]
fn system_a(entities: Entities, resources: Resources) {
// ...
}
#[system(name="system B")]
#[after_name("system A")]
fn system_b(entities: Entities, resources: Resources) {
// ...
}
or:
#[system(name="system A")]
#[before("system_b")]
fn system_a(entities: Entities, resources: Resources) {
// ...
}
#[system(name="system B")]
fn system_b(entities: Entities, resources: Resources) {
// ...
}
or:
#[system(name="system A")]
#[before_name("system B")]
fn system_a(entities: Entities, resources: Resources) {
// ...
}
#[system(name="system B")]
fn system_b(entities: Entities, resources: Resources) {
// ...
}
Which are all equivalent and express that system A needs to run before system B
Barriers
The last tool rin provides to allow systems synchronization are barriers. A barrier is a simple struct with an annotation as:
#[barrier(name = "some barrier")]
pub struct SomeBarrier;
And then added to the scene as:
scene_builder.add_barrier(SomeBarrier);
Then if we had for example some update systems update_A, update_B and update_C and a render_system one way to make all the update systems run before the render system is to make them all run before the barrier using a before dependency on the barrier and then make the render system run after the barrier by using an after dependency on the barrier.
Debugging
Sometimes a system might not run in the order we expected, something might seem to not move or perhaps a jittery movement is sometimes a signal that a system is running in the wrong order.
A useful tool to debug and understand an application order of execution and dependencies is the dependencies graph renderer. Once we've added all the systems to our application we can run:
scene.render_systems_dependency_graph("systems.dot");
And it'll create a systems.dot file which contains the dependency graph for the application. This files can be opened with any GraphViz viewer and if you use visual code as IDE even with an addon for it.
For example the resulting dependencies graph for the modified immediate renderer example looks like:
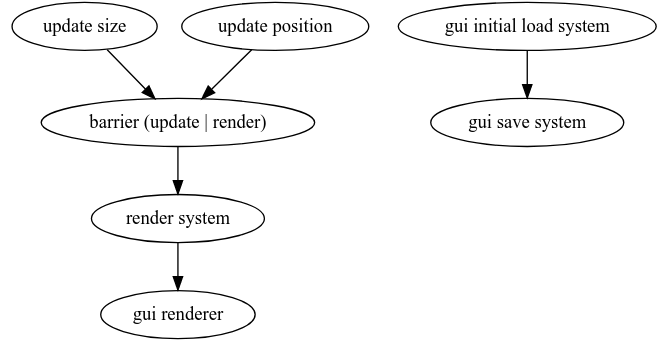
The barrier that appears in the graph is automatically added by rin between update and render systems and allows to easily make all update systems run before the render system even without expressing dependencies. When we add update systems, rin automatically makes them all run before the update | render barrier and when we add render systems they all depend as running after the barrier to ensure that render systems never run before all updates are done.
Parallel systems
Running systems in parallel is usually a performance gain but it creates some problems that we need to deal with, the following sections present three alternatives to work with parallel systems in rin.
Optional dependencies
As we've seen at the beginning marking dependencies is optional. By default a rin application can run without expressing any dependencies and as long as all the systems can run in an undefined order and we depend on the default update | render barrier everything should work without problem.
Even systems that might write to the same component can run simultaneously since rin by default protects them using a read/write lock so if two systems try to access the same component at the same time one of them will be paused until the other is done.
This can be problematic some times, inducing what is call a deadlock. For example system A ends up waiting on system B cause they both try to write to the same resource but then B needs to access data that A already has locked so they both end up waiting each other and the application hangs indefinitely.
The best way to avoid this is expressing the dependencies but when it happens in an application with a few systems it might be hard to find out. To make it easier to debug rin provides a feature, debug_locks, that will make an application, where two systems try to access the same resource for writing simultaneously, panic and give us information about the problem. Then we can easily add the suggested dependencies.
To use it we just need to run our application as:
cargo run --features=rin/debug_locks
Lock free mode
Rin can also be run in lock free mode, in this mode, expressing all dependencies at least as read or write is mandatory. Since it doesn't use any locks it can be faster but also avoids deadlocks since it forces each system to express all the data it writes or reads. This provides rin enough information to order the systems execution in a way where there will never be two simultaneous writes to the same data, either component or resource.
This mode is recommended for more complex applications with multiple systems that need every last bit of performance since avoiding locks will make things faster but also it avoids deadlocks which can be cumbersome to debug in bigger applications.
Some systems types avoid having to express all the dependencies which can make writing systems in this mode a bit less verbose.
To use lock free mode we just need to enable the corresponding feature:
cargo run --features=rin/lock_free
Single threaded mode
Finally even if rin makes using parallel systems relatively easy, managing dependencies or things like deadlocks can end up being cumbersome and make programming too verbose when we want to just do something relatively simple. In those cases we can just remove the multi-threading feature which will get rid of the concurrency problems at once. In this mode we'll just need to express some dependencies to have a correct order of execution.
In order to do that you can just edit your Cargo.toml and from the [dependencies.rin] section remove or comment out "parallel_systems"
Using single threaded mode still allows for other kinds of parallelism that are simpler to use and in a lot of cases even more effective: Instead of running more than one system simultaneously we can iterate and process entities' components in parallel. The section "Parallel iterators" looks a bit into that.
Also since single thread mode avoids using any locks or atomics at all in some cases it might end up being even faster than using multi-threading, mostly when combined with parallel iterators for the most cpu demanding tasks.
Systems types
Although systems always follow the same basic principle: run code that reads and modifies entities' components and resources, the behavior of an application, there's some different types that have particular characteristics that make them more or less indicated for certain situations.
Foreach systems
In the Adding movement chapter we created a system that iterates over every entity that has both a node and a velocity components and changed the node position by adding to it the velocity multiplied by the current frame duration:
#[system_foreach(name = "movement")]
#[updates("Node")]
fn movement(node: Write<Node>, velocity: Read<Velocity>, clock: Res<Clock>) {
let delta = clock.game_time_delta().as_seconds();
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
In that system we used what's called a foreach system. A foreach system, is a function called once per frame for each entity that has all the components indicated by it's parameters. The parameters can be of two types:
-
Operators like
ReadorWritewhich participate in the selection of the entities. For example, since the movement system has bothWrite<Node>andRead<Velocity>it will select every entity that has both these types of data and will allow the system to access theNodefor writing and theVelocityonly for reading. -
Resources by using
ResorResMut. For example in the movement system theClockis a resource that we receive as read only. UsingResMutwe can use a resource for writing to it.
In order to create a foreach system it's mandatory to use the #[system_foreach(name="name")] annotation. Trying to use a simple function with the correct parameters but no annotation to the scene or scene_builder will fail.
A note on resources
Resources are global data that can be accessed from anywhere. They can be added using:
scene.add_resource(my_resource);They are useful for utility objects that we need to use from several systems. The chapter on rin resources explains the topic in more depth and shows which ones are available by default in a rin application.
An advantage of foreach systems is that they already express the components they use and if they use them for reading or writing so except for need / update type of dependencies we don't need to annotate them further.
Plain systems
The most common system in rin is either a function or a struct implementing the System trait. For example the movement foreach system would look like the following when turned into a plain system:
fn movement(entities: Entities, resources: Resources) {
let clock = resources.get::<Clock>().unwrap();
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in entities.iter_for::<(Write<Node>, Write<Velocity>)>() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
}
As can be seen the system is slightly more verbose but it's also more flexible. For example the delta time value is in this case only retrieved once, instead of once per entity as in the foreach example. The cost for this call, game_time_delta(), is negligible but in some cases we might need to do costly calculations common to every entity and a foreach system doesn't allow to them only once.
A plain system can be added without any annotation but can also be annotated so it appears on statistics and to express dependencies:
#[system(name = "movement")]
#[updates("Node")]
#[reads("Velocity", "Clock")]
fn movement(entities: Entities, resources: Resources) {
let clock = resources.get::<Clock>().unwrap();
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in entities.iter_for::<(Write<Node>, Read<Velocity>)>() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
}
The Entities object also allow to access components in more complex or flexible patterns like accessing one specific component for a specific entity, accessing storages which allow certain optimizations in some cases or accessing related components in nested loops.
For example if we wanted to check collisions between every entity with a position and a bounding box component, we would need to iterate through every entity with those components from nested loops, checking every entity for every other entity which a foreach system wouldn't allow.
Another way to implement a plain system is using a struct that implements the rin::ecs::System trait:
struct Movement;
#[system(name = "movement")]
#[updates("Node")]
impl<'a> rin::ecs::System<'a> for Movement {
fn run(&mut self, entities: Entities, resources: Resources) {
let clock = resources.get::<Clock>().unwrap();
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in entities.iter_for::<(Write<Node>, Read<Velocity>)>() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
}
}
The advantage of using this syntax is that a system can keep it's own state without needing to store it in a resource or similar.
Finally a closure that takes the right arguments can also be a system:
scene_builder.add_system(|entities: Entities, resources: Resources| {
let clock = resources.get::<Clock>().unwrap();
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in entities.iter_for::<(Write<Node>, Read<Velocity>)>() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
});
And we can even express dependencies and its name with:
scene_builder
.add_system_with(|entities: Entities, resources: Resources| {
let clock = resources.get::<Clock>().unwrap();
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in entities.iter_for::<(Write<Node>, Read<Velocity>)>() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
})
.name("movement")
.updates::<Node>()
.reads::<Velocity>()
.reads::<Clock>()
.build();
Opposed to foreach systems, plain systems, don't express which components they use in their signature so we need to explicitly do so, mostly when using the lock free mode.
Storage systems
An intermediate type of system between a foreach system, very concise but not very flexible and a plain system, very flexible but very verbose, is a storage system. In an storage system the parameters to the function are storages instead of individual components. This allows to get everything already in the function parameters, automatically express which components the system uses for reading and writing and still have the flexibility of reusing the storages:
#[system_storages(name = "movement")]
#[updates("Node")]
fn movement(query: Sto<(Write<Node>, Read<Velocity>)>, clock: Res<Clock>) {
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in query.iter() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
}
or even:
#[system_storages(name = "movement")]
#[updates("Node")]
fn movement(node: Sto<Write<Node>>, velocity: Sto<Read<Velocity>>, clock: Res<Clock>) {
let delta = clock.game_time_delta().as_seconds();
for (node, velocity) in (&mut node, &velocity).iter() {
let translation = velocity.0 * delta as f32;
node.translate(&translation);
}
}
In the first example we directly retrieve a query that we can use as many times as we want (although not simultaneously since the node is accessed for writing). In the second one we get the storages separately and then we combine them to form a query over all entities that have both components.
Again the first example is a bit simpler but the second is more flexible. In the second example we can use the storages separately and combine them however we want.
In this kind of systems we already express reads and writes in the system signature so there's no need for read / write annotations.
The same way as foreach systems the system_storages annotation is needed for this systems and not using them will fail when adding the system to the scene with:
scene_builder.add_system(movement);
Update systems
Update systems are a very specific type of systems, mostly used when using the immediate renderer model. They simplify dependencies by automatically depending on a barrier so they always run before a renderer and they receive the clock by default since that's almost always needed on update systems.
For example, in the immediate renderer chapter, we created an update system that changes the position of every entity with both position and velocity:
#[update_system(name = "update position")]
fn update_position(clock: &Clock, entities: Entities, resources: Resources) {
let viewport = resources.get::<Viewport>().unwrap();
let delta = clock.game_time_delta().as_seconds() as f32;
for (pos, vel) in entities.iter_for::<(Write<Position>, Write<Velocity>)>() {
pos.0 += vel.0 * delta;
if pos.x < 0. || pos.x > viewport.width as f32 {
vel.x = -vel.x
}
if pos.y < 0. || pos.y > viewport.height as f32 {
vel.y = -vel.y
}
}
}
Apart from receiving the clock as a parameter and auto-depending on a barrier to make them always run before the renderer systems, there's no differences with a plain system.
Render systems
Similar to update systems, render systems are mostly used with immediate renderer applications but in this case they are sometimes also useful in the scene graph like model when we want to draw some simple elements on top of our scene, like some gui elements or some debug information.
We also used them in the immediate renderer chapter:
#[render_system(name = "render system")]
fn render_system(
gl: &gl::Renderer,
viewport: Rect<i32>,
entities: EntitiesThreadLocal,
resources: ResourcesThreadLocal
){
gl.clear(&BLACK);
let gl = gl.with_properties(&[
gl::Property::Blend(true),
gl::Property::BlendFunc(gl::ONE, gl::ONE_MINUS_SRC_ALPHA),
]);
let iter = entities.iter_for::<(
Read<Position>,
Read<Size>,
Read<Color>
)>();
for (pos, size, color) in iter {
gl.draw_circle_fill(pos, size.0 / 2., 30, &color.0)
}
}
In this case the system receives two extra parameters a gl::Renderer and a viewport as a Rect<i32> the gl renderer can be used to draw to the screen and the viewport is sometimes useful if we need to setup the view with a camera or similar.
Apart from that it's usage is the same as that of a plain system. One difference here is that both the entities and the resources are now ThreadLocal. This means that this system will always run in the main thread and that with it's entities and resources we can access components and resources that might not be thread safe.
Thread local systems
As explained in the last section, some times we need to access data that is not thread safe, that can only be accessed from the thread it was created from. This can happen for both entity components and resources. For example gl resources like the renderer itself, textures, buffers ... can only be used from the thread they were created in, so a thread local system is needed. Also some events related types are not thread safe in which case they can only be accessed from a thread local system.
All the systems that we've seen until now have thread local versions. To use them we just need to change their entities and resources to EntitiesThreadLocal and ResourcesThreadLocal respectively. Also the annotations that specify the type and name of system need the _thread_local suffix. So system_foreach becomes system_foreach_thread_local and system becomes system_thread_local
When adding the to the scene we also need to add the _thread_local suffix. so scene.add_system(system) becomes scene.add_system_thread_local(system_tl).
Apart from that their usage is exactly the same as their non thread local versions.
Although thread local systems run in the main thread, other systems might run in parallel with them.
Creation systems
Creation systems are used to create new entities, entities' components and resources once the application is running. Their use is pretty similar to any other plain system:
fn circles_creation_system(entities: CreationProxy, resources: ResourcesThreadLocal) {
entities.new_entity().add(Position(pnt2(0., 0.))).build();
}
That is then added to the scene using:
scene_builder.add_creation_system(circles_creation_system);
Creation systems right now run always on the main thread and always alone with no other system running at the same time. This might change in the future though.
Parallel iterators
Parallel iterators allow to process entities' components in parallel it's an alternative to running systems in parallel although both things can happen simultaneously.
To use parallel iterators we need to retrieve the storage for the component or query that we want to iterate over. Let's for example transform the update position system from the immediate renderer example to run in parallel.
In order to use parallel iterators we need to add the crate rayon to our application:
cargo add rayon
Then we import rayon's prelude from whereever we want to use ti:
use rayon::prelude::*;
Finally let's see how the update system looks converted to use parallel iterators:
#[update_system(name = "update position")]
fn update_position(clock: &Clock, entities: Entities, resources: Resources) {
let viewport = resources.get::<Viewport>().unwrap();
let viewport = viewport.rect();
let delta = clock.game_time_delta().as_seconds() as f32;
let mut storage = entities
.storage_for::<(Write<Position>, Write<Velocity>)>()
.unwrap();
storage.par_iter().for_each(|(pos, vel)|{
pos.0 += vel.0 * delta;
if pos.x < 0. || pos.x > viewport.width as f32 {
vel.x = -vel.x
}
if pos.y < 0. || pos.y > viewport.height as f32 {
vel.y = -vel.y
}
})
}
Now the foreach that updates the circles positions will run in parallel several iterations of the loop accelerating greatly the process. In this case of course given how little information we need to update and how simple the calculus, it's not going to make any difference and might even be slower due to having to send the tasks to the different threads, but for processes where a lot of information needs to be processed, parallel iterators are a really important and easy to use tool.
There's two particularities worth commenting about the example:
-
We need to get the viewport rectangle because the viewport resource can't be directly sent to a different thread. Resources can be thread safe or thread local and so they are protected by a generic smart pointer that is not marked as being thread safe. If we didn't had the line that gets the rectangle from the viewport resource:
let viewport = viewport.rect();The compiler would fail, giving us an error, saying that viewport can't be sent to a different thread, that it's not
Send. -
In order to use parallel iterators we need to first retrieve the storage. We could have also used a storage system as:
#[system_storages(name = "update position")] fn update_position( mut storage: Sto<(Write<Position>, Write<Velocity>)>, viewport: Res<Viewport>, clock: Res<Clock>) { let viewport = viewport.rect(); let delta = clock.game_time_delta().as_seconds() as f32; storage.par_iter().for_each(|(pos, vel)|{ pos.0 += vel.0 * delta; if pos.x < 0. || pos.x > viewport.width as f32 { vel.x = -vel.x } if pos.y < 0. || pos.y > viewport.height as f32 { vel.y = -vel.y } }) }
Parallel iterators use rayon to work so reading through the rayon documentation will give you some insights on how to use them.